
Developing a Retrieval-Augmented Generation (RAG) System for Factual Question-Answering
Introduction
The Retrieval-Augmented Generation (RAG) approach combines retrieval mechanisms with large language models (LLMs) to enhance factual question-answering capabilities by incorporating relevant external documents. This project develops a RAG system to answer questions about Pittsburgh and Carnegie Mellon University (CMU). Our system aims to provide an accessible tool where users can instantly retrieve concise answers from extensive documents without manually searching through them, making it highly valuable for students, researchers, and the general public.
Social Impact: This RAG system revolutionizes how users access information, saving significant time and effort. For students and researchers, it enables quick insights from academic or technical documents, removing barriers to knowledge discovery. By adapting this tool for scientific and engineering domains, it has the potential to accelerate innovation, foster cross-disciplinary collaboration, and democratize access to critical technical knowledge, empowering users worldwide.
Method
This RAG system integrates document retrieval with sequence-to-sequence generation for an end-to-end question-answering framework. My contributions included setting up dataset embeddings, constructing the RAG model pipeline, conducting ablations on datasets and models, and verifying test data accuracy. My teammate managed data scraping, dataset creation with various chunking strategies, crafting Q&A pairs, and initial Q&A pair annotation.
Approach:
- Data Collection: Data was collected from various online sources, covering history, culture, tourism, and other aspects of Pittsburgh and CMU. Using Python libraries, HTML content and PDFs were parsed into plain text.
- Data Preprocessing: Text was cleaned and standardized using tokenization and chunking strategies of 1, 2, 5, 7, and 10 sentences to optimize retrieval performance.
- Embedding Models: Embeddings were generated using two primary models—MiniLM-L6 and BAAI/bge-large-en-v1.5—for document and query representations.
- Language Models: Tested Flan-T5 models of varying sizes to evaluate their performance on retrieval-augmented generation tasks.
- Model Ablations: Tested multiple model configurations for retrieval and generation, varying embedding sizes, language models, and chunking strategies to determine the optimal setup.
RAG System Architecture:
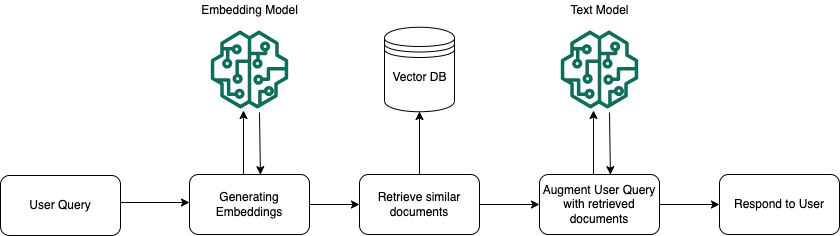
Figure 1: The RAG system integrates retrieval and generation components. Retrieved documents are passed to Flan-T5 for answer generation, with optimal chunking determined by sentence length experiments.
Results
The RAG system’s performance was evaluated using Exact Match (EM) and F1 scores. Key findings include:
- Optimal Chunking Strategy: 5-sentence chunking achieved the highest EM (46.00%) and F1 score (0.62), providing the right balance of context and efficiency.
- Embedding Model Comparison: Switching to BAAI embeddings improved EM by 6%, although this model required significantly more memory.
- Short vs. Long Answers: Short answers (3-4 words) improved EM by 10%, showing that concise responses better align with the evaluation metrics.
- Language Model Performance: Flan-T5-xl outperformed Flan-T5-large, suggesting that larger models offer slight accuracy gains, though at a cost in memory usage.
These results underscore the RAG system’s ability to provide accurate, context-specific answers while remaining efficient, making it suitable for real-time question-answering applications.
Discussion and Future Directions
This project demonstrates that RAG systems can be tailored for specific domains like localized knowledge retrieval, helping users access factual and community-centered information. The open-source structure of this pipeline encourages its adaptation and use in educational contexts.
Future Work:
- Implementing Self-RAG, a refined mechanism that improves accuracy by selectively retrieving only query-relevant information, further increasing response precision and reducing irrelevant content.
- Adapting the RAG system for scientific and technical question-answering to support use cases in engineering and STEM education.
RAG vs. Self-RAG:
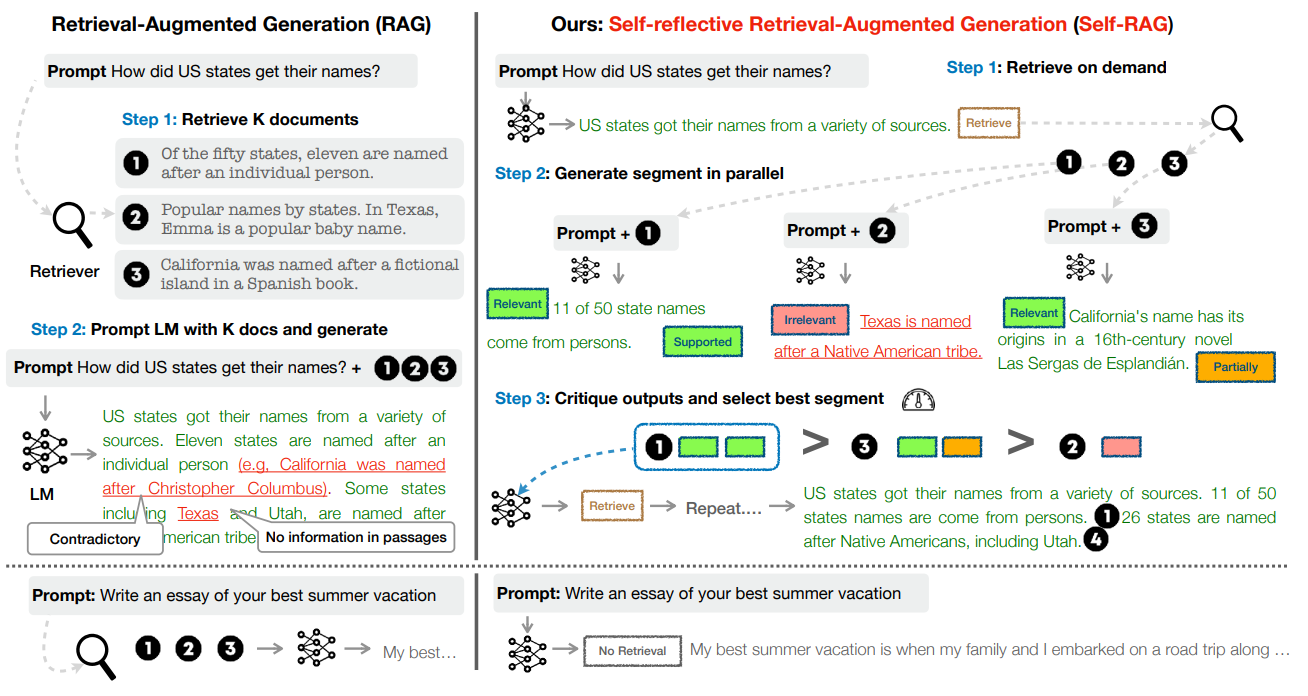
Figure 2: The Self-RAG model selectively retrieves context based on query relevance, enhancing response accuracy and minimizing irrelevant information—a critical feature for specialized domains like engineering question-answering.